
Was ist eine robots.txt – ein kurzer Leitfaden
Inhaltsverzeichnis
Die robots.txt ist eine Textdatei, die Suchmaschinen und AI-Bots Anweisungen gibt, welche Bereiche deiner Website sie crawlen dürfen.
In diesem Artikel erfährst du: Was eine robots.txt Datei ist und wie sie funktioniert, welche Befehle (User-agent, Allow, Disallow) du verwenden kannst, wie sich robots.txt von Meta Robots Tags unterscheidet, wie du die Datei mit Sitemaps kombinierst, wann du robots.txt nicht verwenden solltest und welche Fehler du unbedingt vermeiden musst.
 Hi, ich bin Alexandra Herrmann
Hi, ich bin Alexandra Herrmann
Ich schreibe über Content-Strategien, AI-Search, SEO und digitales Marketing und komme aus Selb im Fichtelgebirge.
Leserdauer dieses Artikels: 3 Min.
Was ist eine robots.txt Datei?
Die robots.txt ist eine einfache Textdatei, die im Hauptverzeichnis deiner Website liegt und Anweisungen für Suchmaschinen-Bots und AI-Bots enthält. Mit ihr kannst du steuern, welche Bereiche deiner Website gecrawlt werden dürfen und welche nicht.
Die Datei kann große Teile deiner Website für Suchmaschinen blockieren, weshalb du besonders vorsichtig bei der Konfiguration sein solltest. Sie sollte immer im Stammverzeichnis deiner Website liegen (z.B. http://www.domain.com/robots.txt) und ist nur für die vollständige Domain gültig, auf der sie sich befindet einschließlich des verwendeten Protokolls (http oder https).
Wenn die Datei falsch konfiguriert ist, kann dies zu erheblichen Problemen führen, wie etwa der versehentlichen Blockierung wichtiger Inhalte.
Gut zu wissen für WordPress-Nutzer: Wenn du ein WordPress-Theme installierst, ist die Datei in der Regel bereits vorhanden. Falls nicht, wird sie durch die Installation eines SEO-Plugins wie RankMath automatisch erstellt.
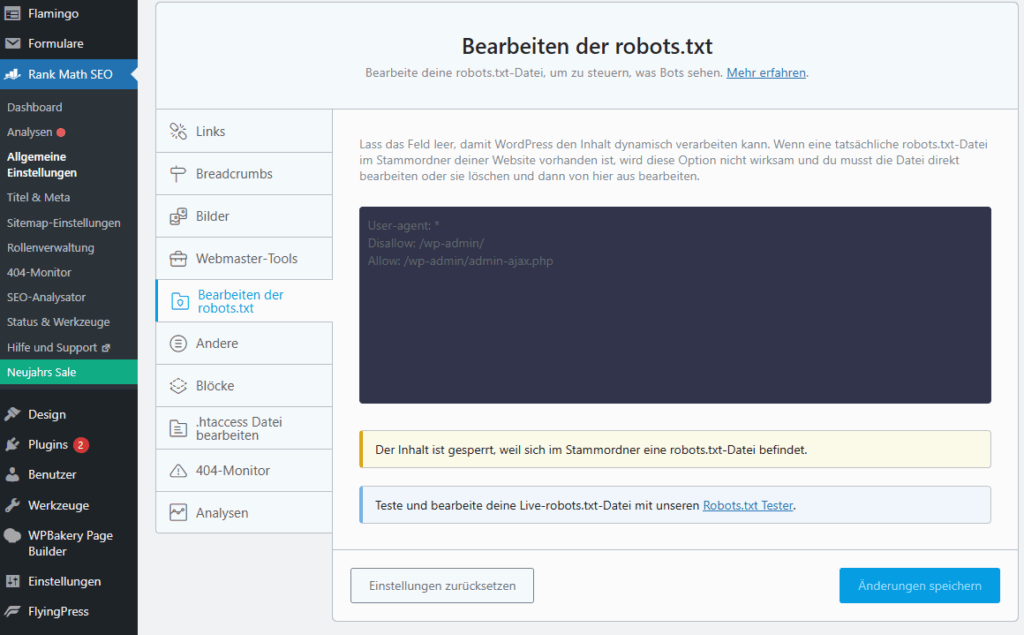
robots.txt-Datei in WordPress RankMath
Du findest die robots.txt auf jeder Website, indem du in deinem Browser einfach www.domain.de/robots.txt eingibst. Suchmaschinen-Crawler lesen diese Datei, bevor sie mit dem Crawlen der Seite beginnen.
Die grundlegende Syntax verstehen
Die Syntax von robots.txt ist einfach gehalten. Hier sind die wichtigsten Elemente, die du kennen solltest:
User-agent
Dieser Befehl gibt an, für welchen Crawler die Anweisungen gelten. In der Datei werden bestimmte „User-agents“ angesprochen, also die spezifischen Crawler der Suchmaschinen.
Beispiele:
User-agent: Googlebot
User-agent: *
Das Sternchen (*) steht dabei für alle Crawler.
Allow und Disallow Befehle
Mit Allow und Disallow werden bestimmte Seiten oder Verzeichnisse für den Crawler freigegeben oder gesperrt.
Zum Beispiel:
Disallow: /seo-wissen/
Allow: /ueber-mich/
Dies bedeutet, dass der Crawler das Verzeichnis /seo-wissen/ nicht besuchen darf, aber /ueber-mich/ schon.
Robots.txt vs. Meta Robots Tags – Was ist der Unterschied?
Während die robots.txt Datei den Suchmaschinen-Crawlern globale Anweisungen gibt, können Meta Robots Tags (index und noindex bzw. Kein Index) auf einer Seite spezifischere Anweisungen erteilen.
Für WordPress-Nutzer: Die Einstellungen findest du, wenn du das Plugin RankMath installierst und deine Seite oder deinen Beitrag im Backend aufrufst. Scrolle einfach zum Plugin-Bereich von RankMath.

RankMath auf Seitenebene oder im Blogbeitrag
Der wesentliche Unterschied: Eine einzelne Seite kann mit einem Meta-Tag von der Indexierung ausgeschlossen werden, während der Rest der Website weiterhin gecrawlt wird. Es wurde seitens Google bereits mehrfach behandelt, dass ein Noindex in der robots.txt nicht bedeutet, dass die Seite aus Google ausgeschlossen wird.
Robots.txt in Kombination mit Sitemaps
Eine gute Praxis ist es, die Sitemap in der robots.txt Datei anzugeben. Dies erleichtert es den Suchmaschinen-Crawlern erheblich, alle relevanten Seiten der Website zu finden.
Sitemap xml im RankMath Plugin
In der robots.txt sollte folgender Hinweis stehen:
Sitemap: https://www.meinewebsite.com/sitemap.xml
Auch die Sitemap.xml kannst du durch RankMath selbst erstellen. Siehe Screenshot aus dem obigen Bild.
Wie man bestimmte Seiten blockiert
Manchmal gibt es bestimmte Seiten, die man vor Suchmaschinen verbergen möchte. Dies kann über den Disallow Befehl in der robots.txt Datei erfolgen.
Ein Beispiel:
Disallow: /produkte/
Beachte: Dadurch wird das Verzeichnis /produkte/ vollständig für Crawler gesperrt – also auch alle darunterliegenden Seiten wie beispielsweise /produkte/produkt1.
Wann sollte man robots.txt nicht verwenden?
Es gibt Fälle, in denen die Verwendung von robots.txt nicht empfohlen wird. Zum Beispiel wenn man verhindern möchte, dass vertrauliche Informationen durch Suchmaschinen gefunden werden. In diesen Fällen ist es besser, die Seiten passwortgeschützt zu machen oder eine andere Plattform zu wählen.
Verwende die robots.txt-Datei nicht, um deine Webseiten (einschließlich PDFs und anderer von Google unterstützter textbasierter Formate) vor der Google Suche zu verbergen.
Warum nicht? Wenn andere Seiten mit beschreibendem Text auf deine Seite verweisen, kann Google die URL auch ohne Seitenaufruf indexieren. Wenn du deine Seite aus den Suchergebnissen ausschließen möchtest, solltest du eine andere Methode wie den Passwortschutz oder noindex auf Seitenebene verwenden.
Was passiert bei einer blockierten Seite?
Wenn deine Seite über eine robots.txt-Datei blockiert ist, kann die URL der Seite zwar weiterhin in den Suchergebnissen erscheinen, aber das betreffende Suchergebnis enthält keine Beschreibung.
Bilddateien, Videodateien, PDFs und andere Nicht-HTML-Dateien, die auf der blockierten Seite eingebettet sind, werden ebenfalls vom Crawling ausgeschlossen, es sei denn, es wird von anderen für das Crawling zulässigen Seiten auf sie verwiesen.
Wenn du dieses Suchergebnis für deine Seite siehst und das Problem beheben möchtest, entferne einfach den robots.txt-Eintrag, der die Seite blockiert.
Fazit
Die robots.txt ist ein mächtiges Werkzeug zur Steuerung von Suchmaschinen-Crawlern und AI-Bots, aber sie muss mit Bedacht eingesetzt werden. Verwende sie für allgemeine Crawling-Anweisungen, kombiniere sie mit deiner Sitemap und nutze für sensible Inhalte andere Schutzmechanismen wie Passwortschutz oder noindex Meta-Tags.
Eine falsch konfigurierte robots.txt kann große Teile deiner Website blockieren und zu erheblichen SEO-Problemen führen. Überprüfe deine Datei daher regelmäßig und teste sie mit den entsprechenden Tools.
Du findest weitere Informationen zu diesem Thema findest du direkt bei Google: https://developers.google.com/crawling/docs/robots-txt/create-robots-txt?hl=de





