
Crawling und Indexierung: so findet Google deine Website
Inhaltsverzeichnis
Crawling bedeutet, dass ein Bot deine Website besucht und prüft, welche technischen Regeln hinter deiner Seite hinterlegt sind.
Crawling und Indexierung sind keine technischen Spielereien, sondern eine Frage der Priorisierung: Welche Inhalte sind für den Bot wirklich wichtig? In diesem Artikel zeige ich dir, wie du Google dabei hilfst, deine wichtigsten Seiten zu finden und unnötige Seiten auszuschließen.
In diesem Artikel erfährst du: Warum Google nicht alle deine URLs crawlen kann, wie du mit der Google Search Console problematische Seiten findest, wann du noindex, robots.txt, Canonical-Tags und nofollow einsetzen solltest, und wie du den Erfolg deiner Optimierungen misst.
 Hi, ich bin Alexandra Herrmann
Hi, ich bin Alexandra Herrmann
Ich schreibe über Content-Strategien, AI-Search, SEO und digitales Marketing und komme aus Selb im Fichtelgebirge.
Leserdauer dieses Artikels: 5 Min.
Warum Crawling-Optimierung wichtig ist
Google kann nicht jede URL unbegrenzt crawlen. Irgendwann wird ein Crawl abgebrochen, wenn deine Seite zum Beispiel zu lange braucht, damit alle Inhalte gefunden werden. Google muss auch hier Ressourcen sparen.
Deswegen macht man zum Beispiel mehrere Sitemaps oder versucht, in der robots.txt bestimmte Befehle zu geben, welche Seiten wichtig sind und welche nicht. Damit eben zum Beispiel Produktseiten alle im Index erfasst werden und Seiten, die nicht so wichtig sind, eben später oder gar nicht gecrawlt werden.
Warum werden unnötige URLs ein Problem?
Viele Webseiten erzeugen automatisch URLs, die keinen Mehrwert bringen. Zum Beispiel wenn Produkte verschiedene Farben haben oder verschiedene Produktvarianten sind, das passiert in Shops eben ganz oft. Dann werden unendlich viele URLs automatisiert erstellt und dann passiert es auch, dass ein Crawl abgebrochen wird.
Typische URL-Probleme erkennst du an:
– Parametern in der URL (z.B. ?filter, ?sort_by)
– Seitenzahlen (z.B. ?page=1, ?page=2)
– Filtern und Sortierungen
– Suchbegriffe in der URL
– Farbvarianten und Produktvarianten
Diese URLs erzeugen viele Varianten, aber keinen neuen Inhalt. Deswegen ist es auch hier wichtig, dass du solche automatisch generierten Seiten vom Crawling möglichst ausschließt.
Die Rolle der Google Search Console
Die Google Search Console ist der wichtigste Ausgangspunkt, um solche Seiten zu finden. Besonders wertvoll sind Berichte zu alternativen Seiten mit Canonical, Duplicate Content oder nicht indexierten Seiten.
Da siehst du eben in der Google Search Console, wo Google sein Crawling verwendet – auf welchen Seiten, welche Seiten findet er und welche Seiten findet er nicht. Deswegen musst du auch immer mal in die Google Search Console in die Indexierung reingucken, um zu verstehen, welche Seiten gecrawlt werden und welche nicht.
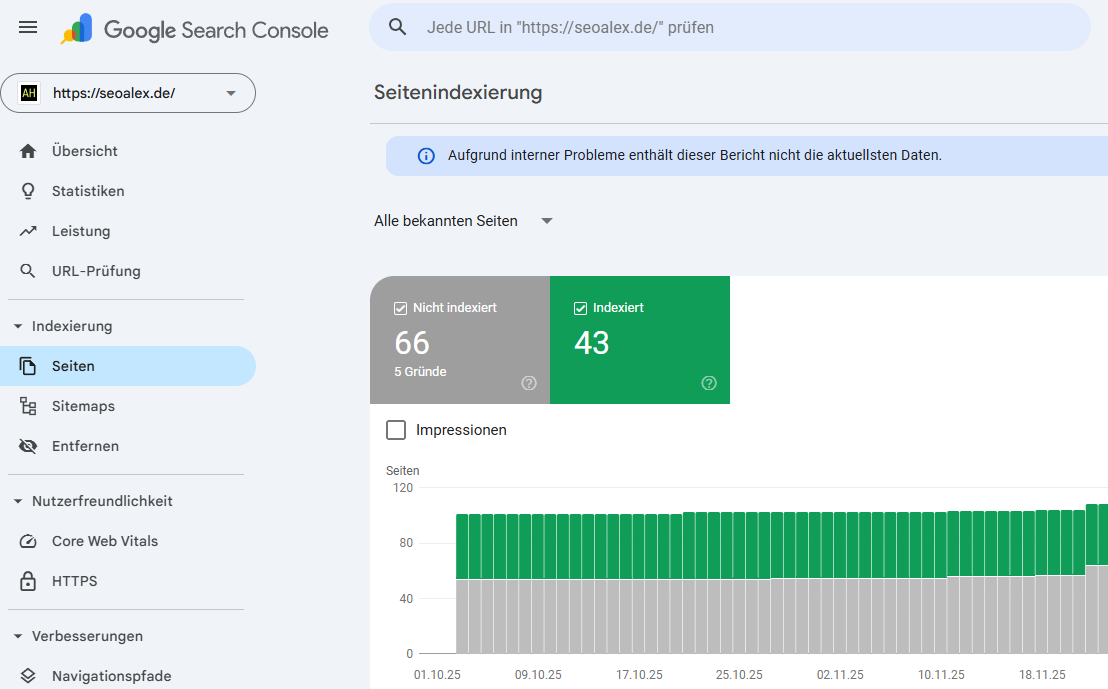
Google Search Console Seiten Indexierung Übersicht
So findest du problematische Seiten in der Search Console
1. Gehe zu „Seiten“ (unter Indexierung)
Hier findest du verschiedene Berichte, die dir zeigen, welche Seiten Probleme haben.
2. Schaue dir „Alternative Seite mit richtigem Canonical-Tag“ an
Dieser Bericht ist die Goldmine für deine Problemseiten! Diese Seiten sind kanonisiert zu ihrer Hauptversion, um Duplikate zu vermeiden. Gehe die URLs durch und notiere dir alle URL-Parameter, die du findest.
Typische Parameter, die du blockieren solltest:
– ?undefined
– ?page=1, ?page=2, ?page=3
– ?filter
– ?sort_by
– ?color, ?size
– /search (interne Suche)
Filter-URLs werden über die robots.txt vom Crawling ausgeschlossen, nicht über Noindex.
3. Füge einen URL-Filter mit „?“ hinzu:
Wenn du einen URL-Filter mit dem Fragezeichen (?) anwendest, siehst du alle URLs mit Parametern. Du findest vielleicht sogar stärkere Kandidaten wie ganze Unterordner (z.B. /search).
4. Wiederhole den Prozess mit anderen Berichten:
– Entdeckt, zurzeit nicht indexiert
– Durch ’noindex‘ Tag ausgeschlossen
– Indexiert, obwohl durch robots.txt blockiert
Die wichtigsten Werkzeuge im Überblick
Lass mich dir die wichtigsten SEO-Elemente erklären, die du für die Crawling-Optimierung nutzen kannst:
Noindex – Seiten vom Ranking ausschließen
Noindex bedeutet: Die Seite darf prinzipiell existieren, aber sie sollte nicht in den Suchergebnissen erscheinen.
Wann ist noindex sinnvoll?
– Wenn du zum Beispiel spezielle Landing Pages für Google Ads machst, aber schon eine andere Seite für die organische Suche aufgearbeitet hast
– Für veraltete Inhalte, die sowieso nicht mehr geklickt werden oder auch nicht in den Top-Platzierungen erscheinen
– Wenn du intern deinen User durch die Seite führen willst, also auf den Inhalt verlinken möchtest, aber die Suchmaschine soll die Seite nicht mehr anzeigen
Wenn du Seiten aus dem Index entfernen willst, musst du zuerst noindex setzen, Google die Seiten entfernen lassen und dann erst in der robots.txt blockieren. Wenn du zuerst blockierst, sieht Google das noindex-Tag nie!
Robots.txt – Google vom Crawlen abhalten
Zur robots.txt habe ich bereits einen eigenen Beitrag gemacht, den verlinke ich dir hier nochmal. Kurz und knapp: Das ist einfach eine Anleitung für den Bot, welche Seiten er crawlen darf und welche nicht.
So blockierst du Parameter in der robots.txt:
Gruppiere deine problematischen URLs nach Mustern.
Zum Beispiel:
User-agent: *
Disallow: /*?undefined
Disallow: /*?page
Disallow: /search
Disallow: /*?ref
Disallow: /*?trk
Bevor du Disallow-Regeln hinzufügst, sei dir absolut sicher, dass du nicht versehentlich wichtige Seiten blockierst! Du kannst Tools wie realrobotstxt.com nutzen, um die Regeln zu testen.
Canonical – Die Hauptversion festlegen
Canonical sagt Google, welche Version einer Seite die Hauptversion ist. Das ist wichtig, wenn du zum Beispiel Varianten hast, Sortierungen oder ähnliche URLs.
Das Ziel ist einfach: Alle Signale auf eine Seite zu bündeln und Duplicate Content zu vermeiden.
Und wichtig: Canonical heißt nicht, dass Google das nicht crawlen darf. Es ist einfach nur eine Empfehlung: „Hier ist die eigentlich wichtigere Seite, die alle Informationen enthält.“
Du kannst mit Canonical-Tags auf Duplikaten oder Varianten arbeiten, die auf ihre Hauptversion zeigen. Das konsolidiert die Signale und eliminiert Duplikations-Probleme.
Nofollow – Links entwerten
Nofollow bedeutet, dass Google einem Link nicht folgen soll. Das kann auch helfen, Crawling für irrelevante Pfade zu reduzieren.
Allerdings: Das funktioniert nur wenn du konsequent bist! Sobald dieselben URLs anderswo ohne nofollow verlinkt sind, kann Google sie trotzdem finden.
Du musst also wirklich überall nofollow setzen, wo diese URLs verlinkt sind, sonst bringt es nichts.
Die Entscheidungshilfe im Kopf behalten
Die Entscheidung ist eigentlich einfach:
– Noindex: Wenn eine Seite nicht ranken soll, aber intern noch nützlich ist
– Canonical: Wenn es nur eine Variante ist und du Signale bündeln willst
– Nofollow: Wenn Links entwertet werden sollen
– Robots.txt: Wenn Google gar nicht erst crawlen soll
Deinen Erfolg messen
Deinen Erfolg kannst du letztendlich in der Search Console ansehen. Du kannst auch Screaming Frog nutzen, der deine Seite crawlt, oder auch Firecrawl.
Damit erkennst du, was solche Bots sehen, wenn sie deine Seite crawlen, und du kannst nach Problemen gucken. Was passiert da im Hintergrund?

Screaming Frog Crawl HTML Seiten
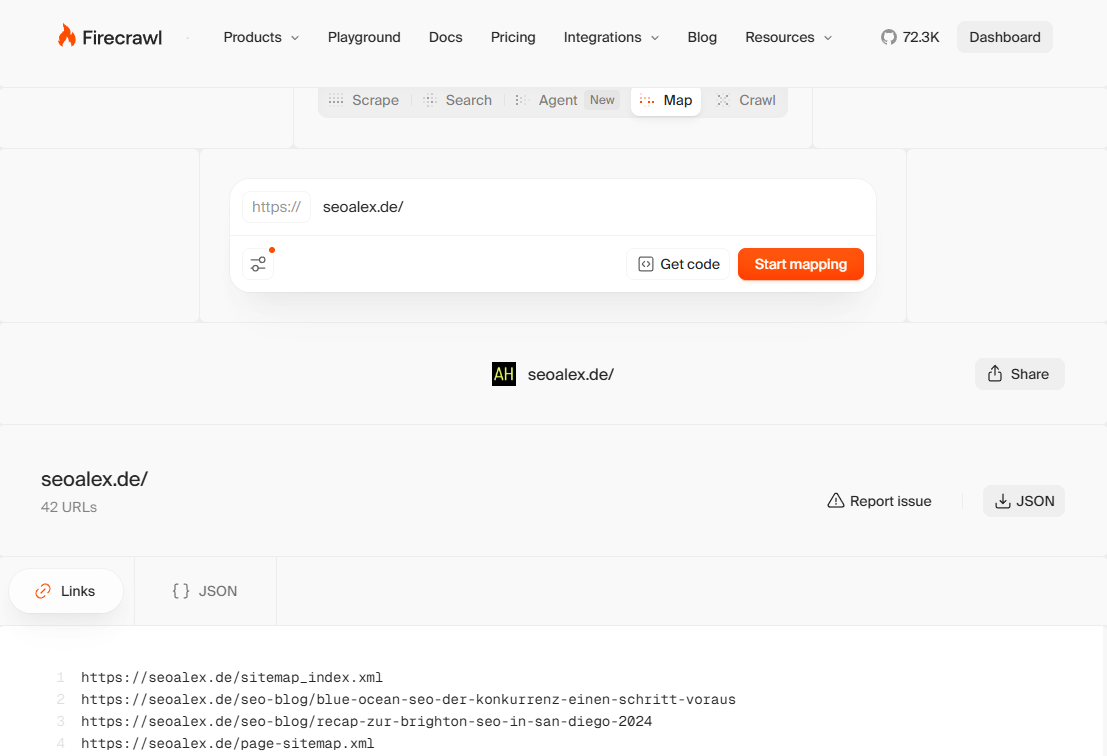
Firecrawl HTML Seiten
Nach ein paar Wochen solltest du prüfen:
– Indexierungs-Berichte: Werden die richtigen Seiten indexiert?
– Anzahl der indexierten Seiten: Hat sich die Anzahl wichtiger Seiten erhöht?
– Crawl-Statistiken: Crawlt Google jetzt häufiger deine wichtigen Seiten?
Ich hatte nach der Domainumstellung ein Problem mit dem Crawling gehabt. Das war ein interner WordPress-Fehler, den ich noch nicht kannte. Durch das Crawling habe ich gemerkt, dass der Bot eben nicht alle Seiten erfassen kann, und habe das Problem dann gelöst. Das war nicht so schwer, und dann zwei Wochen später habe ich dann auch schon den Erfolg gesehen, dass meine Seite zu ranken begonnen hat.
Was ich grundsätzlich über Crawling sagen kann
Das Crawling – der Bot kommt und guckt: Welche technischen Regeln sind hinter deiner Seite hinterlegt?
Also gibt es zum Beispiel eine robots.txt, an die ich mich orientieren kann? Werden Inhalte indexiert oder dürfen Inhalte nicht indexiert werden? Gibt es Inhalte, die ein Canonical haben? Gibt es Inhalte, die follow oder nofollow sind?
Es gibt eben hier ganz verschiedene Regeln, die ein Bot nutzen kann, wie er deine Seite crawlt.
Das Erste ist immer zu prüfen: Kann deine Seite ranken oder nicht? Und das ist auch immer ein Part in meinen Projekten, welches ich als Erstes prüfe. Meistens kann man hier schon einfach Probleme beseitigen.
Fazit
Crawling-Optimierung ist kein Hexenwerk, sondern eine Frage der richtigen Priorisierung. Nutze die Google Search Console, um problematische URLs zu finden, setze die richtigen technischen Elemente ein (noindex, robots.txt, canonical, nofollow) und messe regelmäßig deinen Erfolg.
Mittelgroße bis große Websites profitieren davon besonders stark. Du wirst sehen: Google crawlt häufiger, findet neue Seiten schneller und konzentriert sich auf das Wesentliche – deine wichtigen Inhalte!
Weiter Informationen findest du bei Google: https://developers.google.com/crawling/docs/crawl-budget
https://developers.google.com/crawling/docs/faceted-navigation





